
음악 구조 분석
관련링크
본문
빠른 음악 추천/검색을 위해 음악 특성 벡터의 효율적인 저장 방법을 고려해야 한다. 기존의 방식은 음악 특성 벡터의 빈번한 변화로 인해 특성이 일정하다고 볼 수 있는 짧은 시간 단위 (30ms~500ms)로 샘플링을 진행한다. 짧은 시간 단위의 샘플링으로 인하여 중복되는 특성이 있음에도 불구하고 긴 길이 (400~8,000개의 벡터 집합)를 갖는 데이터를 저장한다.
본 연구실은 기존 시스템의 공간적 낭비가 심하고 검색/추천 시 소요되는 계산량 및 시간이 크는 문제점을 해결하기 위해, 반복되는 구간과 변화가 없는 구간을 음악 특성을 바탕으로 인식하여 반복되는 특성 벡터들을 일정한 구조로 저장할 수 있는 알고리즘을 개발한다.
● 음악 구조 시각화
- 추출된 특성 벡터를 Self-Similarity Matrix(SSM)를 통하여 한 음악의 유사한 부분 검출 및 음악 구조의 시각화가 가능하도록 개발하였다. Self-Similarity Matrix(SSM) 기법은 음악의 유사한 부분을 검출하기 위해 시간에 따라 벡터안의 데이터를 비교하여 검출 한다. 데이터 비교 값들을 기반으로 매트릭스(N x N)를 생성한다.
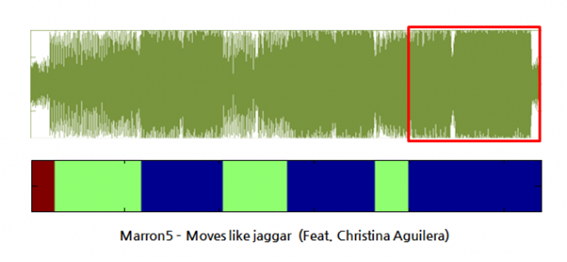
그림 1 음악 구조의 시각화
● 음악의 유사도 검출
- 한 곡의 노래에 대하여 특성 벡터를 추출 후, 추출된 특성 벡터 안의 N개의 데이터를 코사인 유사도(Cosine Similarity)를 계산하여 매트릭스(N x N)를 생성하였다. 코사인 유사도(Cosine Similarity)는 벡터 안의 N개의 데이터들을 비교하고 유사도를 구하는데 많이 사용하는 기법이다.
● 반복 구간 및 유사 구간 검출
- 그림의 적색 부분은 유사한 부분으로 해당 영역을 정확히 찾아냄으로써, 음악의 반복되는 구간, 유사한 구간을 알아낼 수 있고, 이를 구조화하는 연구를 수행하였다. 그림의 3&5에 해당되는 부분은 특성 벡터 안에 있는 3번째 데이터와 5번째 데이터의 유사도를 나타낸다. 매트릭스(N x N) 으로 구성된 아래 그림으로 벡터의 모든 데이터들의 유사도를 확인 할 수 있다.
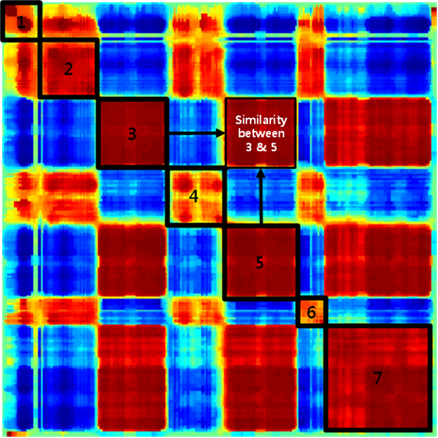
그림 2 음악의 반복 구간 및 유사 구간 검출